The Log: What Every DevOps engineer should now about real time data

I found this article while reading Apache Kafka documentation. Sharing some excerpts from it for DevOps engineers as it seems as a MUST KNOW kind of information for me:
https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
What Is a Log?
A log is the simplest possible storage abstraction. It is an append-only, totally-ordered sequence of records ordered by time.
So, a log is not all that different from a file or a table. A file is an array of bytes, a table is an array of records, and a log is really just a kind of table or file where the records are sorted by time.
Logs in distributed systems
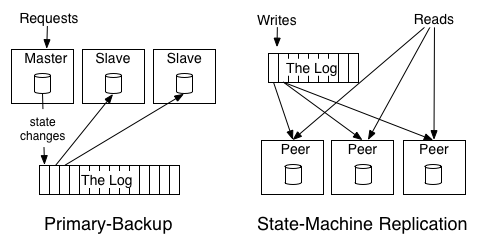
The log-centric approach to distributed systems arises from a simple observation that I will call the State Machine Replication Principle:
If two identical, deterministic processes begin in the same state and get the same inputs in the same order, they will produce the same output and end in the same state.
Deterministic means that the processing isn't timing dependent and doesn't let any other "out of band" input influence its results.
Two processing and replication approaches:
- primary-backup model
- active-active model (state-machine replication)